🎯 摘要:本文以架构师和开发者的双重视角,深入拆解如何打造一套可用垂直智能体系统。文章重点探索架构边界、证据链组织、服务分层和长链路可运维性。
这套实践背后对应的产品,就是虾米选品 (xiamimate.com) · 专为跨境电商卖家打造的选品智能体。
📌 目录
- 引言:脱离 Prompt 的幻觉,回到工程的现实
- 一. 场景本质:为什么垂直选品不是一次聊天,而是一场证据拼图?
- 二. 设计锚点:工业级垂直 Agent 需要怎样的系统约束?
- 三. 全局概览:六层体系支撑下的“选品操作系统”
- 四. 深度剖析:从浏览器最外侧的“薄层”到离线数据“工厂”
- 五. 核心链路运行:问答、报告与离线生产的“三轨并行”
- 六. 请求穿透:当用户敲下 Enter,系统内部发生了什么?
- 七. 痛点抉择:我们在垂直 AGI 落地中的几次硬核架构妥协
- 八. 边界思维:什么是 AI 能力在商业系统中的安全区与无人区?
- 九. 演进罗盘:垂直智能体要啃下的下一个工程硬骨头
- 写在最后:不只做聊天机器人,要做跨境电商的重型装配线
引言:脱离 Prompt 的幻觉,回到工程的现实
几乎每个 AI 产品的第一版,都长得像一个“会聊天的 Demo”:套一个模型、写几段 prompt、接一个对话框,看起来就能跑。但当它要真正变成一个能交付、能计费、能长期维护的产品时,麻烦才刚刚开始 📖。
这篇文章,是我把一个跨境选品 Agent 从 Demo 推向工业级垂直智能体系统过程中的实践笔记。我想聊的不是“模型答得好不好”,而是更靠工程的那一面——为什么一个聊天接口,撑不起一个真正的产品。
在我看来,垂直智能体真正的难点从来不在 prompt,而在四件事:架构边界、证据链组织、服务分层、可运维性 🛠️。后面的内容,基本都是围绕这条主线展开的。
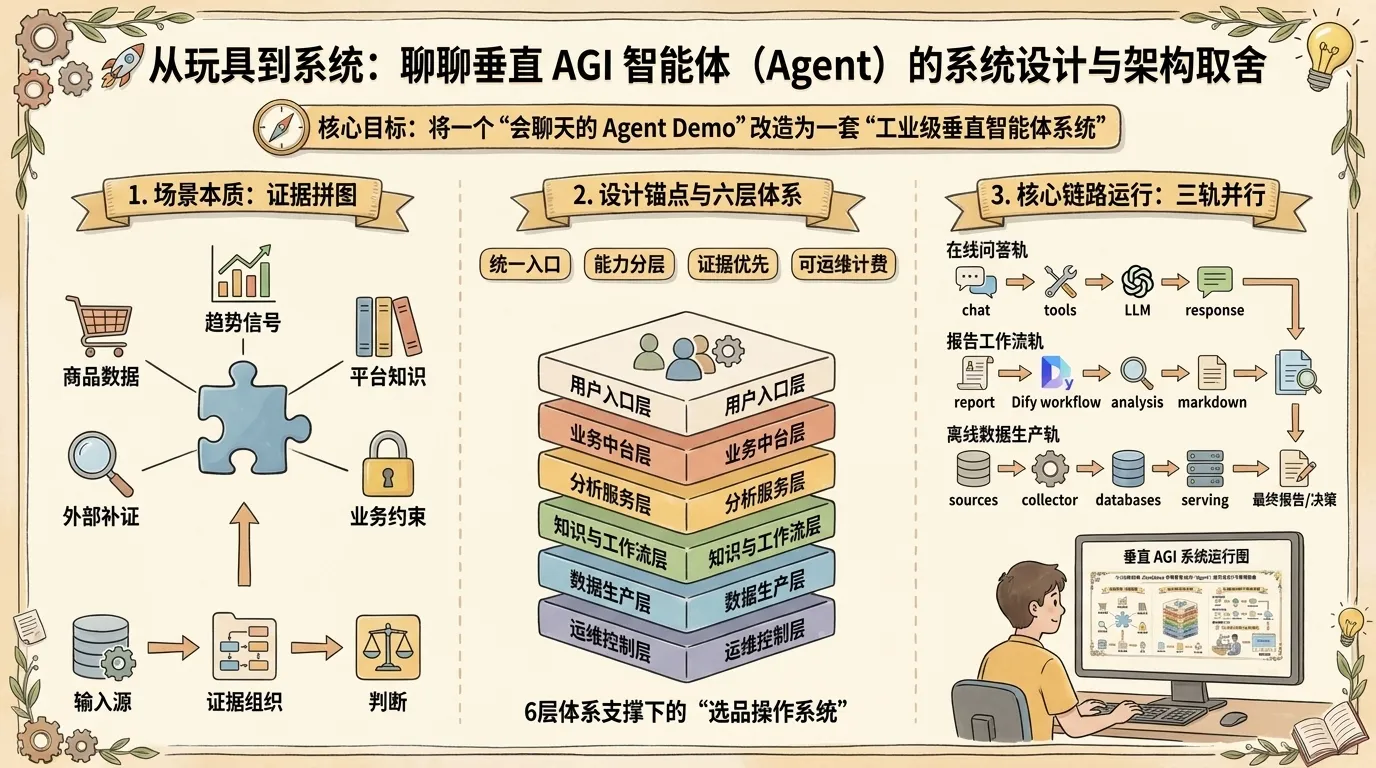
一. 场景本质:为什么垂直选品不是一次聊天,而是一场证据拼图?
这一节先回答场景本身的复杂性:为什么选品不是一次问答,而是一场证据组织工作。
跨境选品这个场景和通用问答最大的不同,在于它不是一个“知道答案就输出”的问题,而是一个“必须先组织证据,再给出判断”的问题 🧩。
一次像样的选品分析,至少会同时依赖几类输入:
- 商品数据 📊:销量、价格、评论、BSR、品牌分布、类目结构。
- 趋势信号 📈:Google Trends、时间窗口内的热度波动、节奏变化。
- 平台知识 🌍:Amazon、TikTok Shop、Temu 的规则、履约、内容、合规差异。
- 外部补证 🌐:公开网页、政策、热点、风险信息。
- 业务约束 🔒:用户身份、积分余额、报告档位、是否允许调用某类能力。
这意味着系统不能只依赖一次 LLM 调用。它需要一个完整的服务体系去回答三个前置问题:
- 这次请求应该走哪条链路? 🤔
- 这条链路里哪些工具是真实可用、稳定可用、允许当前用户使用的? 🛠️
- 最终回答是普通问答、原生工具结果,还是正式报告工件? 📄
这也是“虾米选品”当前架构设计的出发点 🚀。
二. 设计锚点:工业级垂直 Agent 需要怎样的系统约束?
这一节不展开实现细节,只聚焦一个问题:工业级垂直 Agent 到底需要满足哪些系统约束。
我给这个系统定的目标,从来不是“尽快把模型接上去”,而是尽量把智能体做成一条可验证、可扩展、可运营的服务链 ⚓。
当前架构主要服务于四个目标:
2.1 统一入口 🌐
无论用户是发起普通问答、工具调用还是正式报告,入口都尽量统一,避免用户在多个系统之间切换 👥。
2.2 能力分层 🧱
对外看到的是一个智能体,对内则必须明确区分入口代理、用户上下文、工具路由、分析服务、工作流系统和数据生产系统 🧱。
2.3 证据优先 🔍
系统优先返回基于结构化工具和工作流编排得到的结论,而不是把所有内容都交给模型自由发挥 🏷️。
2.4 可运维和可计费 📈
这个系统不是 demo。它要处理用户身份、套餐、积分、工作流扣费、失败恢复、服务监控和部署边界,因此架构上必须留出中台和控制面的职责 💰。
三. 全局概览:六层体系支撑下的“选品操作系统”
这一节先给出全景图:用户请求如何穿过六层架构,最终落到分析、工作流和数据生产系统。
从当前服务解耦和架构演进形态来看,整个智能体系统拆解成了一套清晰的六层架构 🌐:
🖥️ 用户入口层:Open WebUI / Nginx / Portal
🧠 业务中台层:chat-backend
📊 分析服务层:theme-api
⚙️ 知识与工作流层:Dify / RAG / report DSL
🏭 数据生产层:collector / data-infra / runtime / forecast model
🎛️ 运维控制层:control-plane / scripts / monitors如果画成系统图,大致是下面这个样子 📊:
┌───────────────────────────────────┐
│ 🌐 用户浏览器 (Browser) │
└─────────────────┬─────────────────┘
│
▼
┌───────────────────────────────────┐
│ 🖥️ 统一入口:Caddy / Nginx / Portal │◀────────┐
└─────────────────┬─────────────────┘ │
│ │
▼ │
┌───────────────────────────────────┐ │ 运维 / 控制
│ 🧠 业务中台网关:chat-backend │◀─────┐ │ 🎛️ control-plane
└─────────┬───────────────────┬─────┘ │ │
│ │ │ │
▼ ▼ │ │
┌───────────────────┐ ┌─────────────┐ │ │
│ 📊 分析服务层 │ │ ⚙️ 知识/工作流 │ │ │
│ (theme-api) │ │ (Dify/RAG) │ │ │
└─────────┬─────────┘ └───────┬─────┘ │ │
│ │ │ │
▼ ▼ │ │
┌───────────────────────────────────┐ │ │
│ 🗄️ PostgreSQL (Serving Data) │ │ │
└─────────────────▲─────────────────┘ │ │
│ │ │
┌─────────────────┴─────────────────┐ │ │
│ 💾 DuckDB (Runtime 中间层) │ │ │
└─────────────────▲─────────────────┘ │ │
│ │ │
┌─────────────────┴─────────────────┐ │ │
│ 🏭 数据生产层 (collector) │◀─────┘──┘
└───────────────────────────────────┘这个拆法的关键,不是为了追求“微服务感”,而是为了把职责边界从一开始拆清楚 🧱。
四. 深度剖析:从浏览器最外侧的“薄层”到离线数据“工厂”
这一节按六层逐层展开,重点不是罗列组件,而是解释每一层分别负责什么、为什么必须单独存在。
4.1 用户入口层:Open WebUI、Nginx、Portal 🖥️
入口层不做任何业务判断,它只负责一件事:把用户稳稳接进来——承接访问、会话、静态页面和统一导航 🌐。
这一层当前主要负责:
- 承接根路径和 Open WebUI 对话页面。
- 暴露 Portal 页面,例如产品页、指南页、套餐页、工具页和账户页。
- 通过同域代理暴露 Dify chatbot 和相关前端资源。
- 为浏览器隐藏后端服务细节,让用户始终通过统一域名和统一站点结构访问产品。
我刻意把入口层做得很薄。原因很简单:它适合做代理、鉴权承接和页面装配,绝不适合承载复杂业务逻辑 🛡️。
4.2 业务中台层:chat-backend 🧠
如果说入口层负责“接住用户”,那 chat-backend 负责**“理解这次请求在产品体系里意味着什么”** 🧠。
它不是一个单纯的 BFF,而是整个系统的业务网关。当前主要职责包括:
- 读取和维护用户身份、账户、积分、套餐、订单、订阅和使用记录。
- 决定一次请求是否允许继续执行,以及该走哪种 provider 或工作流。
- 为 Open WebUI、Pipelines、Portal 页面和内部服务提供统一业务上下文。
- 承接内部 provider proxy,例如 web search、外部知识库、report workflow 等。
- 作为入口层与分析层之间的策略和边界层。
这里藏着一个很关键的架构决策:theme-api 不直接暴露给浏览器,也不挂在入口 Nginx 前面,而是统一收敛到 chat-backend 之后做路由和上下文治理 🔀。
4.3 分析服务层:theme-api 📊
theme-api 是整套系统里最核心的结构化分析服务 📊。
它提供的不是“聊天答案”,而是一组可被上层编排的分析能力,例如:
- 主题解析与候选池召回。
- 候选池统计和质量诊断。
- 候选池趋势分析。
- 类目 benchmark。
- Top ASIN drilldown。
- 销量预测与解释字段消费。
- 机会发现相关能力。
这层的职责,是把选品分析里稳定、可复用的部分结构化、接口化。只有这样,上层 agent 和 report workflow 才能建立在可验证证据之上,而不是反复要求模型“自己理解数据” 🔍。
4.4 知识与工作流层:Dify、RAG、Report DSL ⚙️
这层承接的不是单次 API 调用,而是更重的长链路编排和知识沉淀 ⚙️。
它当前主要做两件事:
- 用 Dify Workflow 承接 report quick、standard、deep 等分层报告流。
- 用知识库和 RAG 系统承接平台规则、经验知识和文档类补证。
这里的核心价值不在于“用了 Dify”,而在于把长链路分析沉淀成了独立可编排、可调试、可分层计费的工作流资产 🏷️。
4.5 数据生产层:collector、data-infra、runtime、forecast model 🏭
智能体最终能不能给出像样的结论,底层完全取决于数据生产是否稳定 🏭。
当前数据生产链路的大致职责是:
collector负责采集、同步、主题特征处理和部分离线分析任务。DuckDB承接本地或中间态分析数据。PostgreSQL承接 serving 侧可查询数据和业务数据。forecast model产出销量预测结果,供在线分析只读消费。
我喜欢把这层理解成一座“证据工厂”:一旦数据链不稳定,上层所有智能体行为都会退化成语言幻觉的包装 🧊。
4.6 运维控制层:control-plane 🎛️
control-plane 的存在,是为了让整个系统不只是“能跑”,而是“能被管理” 🎛️。
这一层当前负责:
- 统一文档和运行手册。
- 运行时监控与健康检查。
- 跨仓库工作区组织。
- 部署与切换脚本。
- 关键工作流 DSL 和系统装配说明。
对一个多仓库、多服务的智能体系统来说,没有控制面,就谈不上把系统当成产品长期维护 🛡️。
五. 核心链路运行:问答、报告与离线生产的“三轨并行”
如果把系统看成一条装配线,这一节讲的就是三条最关键的运行轨道。
我把当前系统最核心的事件路径划分为三条:在线问答与即时工具调用轨、分层报告工作流编排轨、以及离线数据工厂清洗生产轨 ⚡。
5.1 在线问答与工具链路 💬
这是用户最常触发的路径。
🙋 用户提问
-> 💬 Open WebUI
-> 🔀 Pipelines
-> 🧠 chat-backend
-> 📊 theme-api / 🌐 外部 provider / 📚 知识库
-> 🤖 LLM 综合回答
-> 📡 Open WebUI 流式返回这个链路的架构重点有两个:
- 工具调用必须经过中台和策略层,而不是由前端直连分析服务 🛡️。
- 最终答案可以是自然语言,但中间证据尽量来自结构化工具 🔍。
5.2 报告工作流链路 📄
当用户发起正式分析,例如 report quick 或 report standard,系统会切入另一条更重的工作流路径 📄。
📝 /report quick|standard|deep 商品主题
-> 🔀 Pipelines 解析档位
-> 🧠 chat-backend 处理计费与上下文
-> ⚙️ Dify Report Workflow
-> 📊 theme-api / 📚 知识库 / 🌐 Tavily / 🤖 LLM 节点
-> 📄 Markdown 报告
-> 🗃️ 运行记录与工件持久化这条链路和普通问答最大的不同,是它的目标不是“回复一句话”,而是产出一份正式报告工件。也正因为如此,它必须有更明确的门禁、失败路径和计费语义 🏷️。
5.3 离线数据生产链路 🔄
在线能力之所以能成立,是因为离线链路持续在喂数 🔄。
📥 Keepa / Google Trends / 手工导入
-> 🏭 collector
-> 💾 DuckDB
-> 🗄️ PostgreSQL sync / serving
-> 📊 theme-api 在线只读消费
-> 🤖 agent / 📄 report 使用我刻意把这条链路和在线链路分开,是因为它们的工程约束完全不同。在线链路要解决延迟、鉴权、计费和用户体验;离线链路要解决采集稳定性、数据一致性和可重复生产 ⚙️。
六. 请求穿透:当用户敲下 Enter,系统内部发生了什么?
这一节把一次真实请求拆开,按路径看清它从输入到结果返回的内部穿梭过程。
以“分析 kitchen organizer”为例,一次典型请求的内部“穿梭之旅”大致如下 🚀:
- 用户从统一站点入口发起请求 🖥️。
- Nginx 和 Open WebUI 承接会话与页面交互。
- Pipelines 判断这是普通问答、工具请求还是 report 请求。
chat-backend读取用户身份、积分和运行上下文,并决定后续路由 🧠。- 如果需要结构化分析,就调用
theme-api的候选池、统计、趋势、benchmark 或 Top ASIN 能力 📊。 - 如果需要知识补证或外部搜索,就走知识库、Tavily 或其他 provider 🌐。
- 如果是报告请求,则转入 Dify workflow 编排节点 ⚙️。
- 最终将结构化证据压缩成流式回答或 Markdown 报告返回前端 📄。
这个流程里最关键的不是“调了几个接口”,而是每一段都在做不同类型的职责收敛:入口层收敛访问,中台收敛策略,分析层收敛结构化能力,工作流层收敛长链路编排 🧱。
七. 痛点抉择:我们在垂直 AGI 落地中的几次硬核架构妥协
这一节不讲理想化蓝图,只讲已经做出的几次关键架构取舍。
从作者视角看,当前架构里有几个取舍是非常关键的 ⚖️。
7.1 不让浏览器直连分析服务 🛡️
theme-api 当前不直接作为前端代理目标暴露,而是尽量放在 chat-backend 之后。这让用户上下文、配额、权限、provider 选择和未来的审计逻辑都能放在一层里处理 🛡️。
7.2 把 chat-backend 做成业务网关,而不是纯页面后端 🔀
如果 chat-backend 只做 portal HTML,那它的存在意义很弱。真正让它成立的,是它把身份、账户、计费、工作流代理和 provider 路由统一起来了 🧠。
7.3 报告分层按能力卖点,而不是按 prompt 长短分层 💰
这件事从产品上看像定价问题,从技术上看其实是工作流边界问题。quick、standard、deep 的差异,不应该只是 prompt 更长,而应该对应不同的节点能力、证据范围和失败语义 📄。
7.4 把智能体当系统工程,而不是 prompt 工程 🛠️
我越来越确信,垂直智能体的核心竞争力不在于“谁的 prompt 更花”,而在于:
- 能不能把稳定能力接口化 ⚙️。
- 能不能把长链路工作流化 🧱。
- 能不能把数据链路做成持续供给 🏭。
- 能不能把产品运行边界和运维边界拆清楚 🎛️。
八. 边界思维:什么是 AI 能力在商业系统中的安全区与无人区?
这一节回答一个现实问题:哪些能力已经进入稳定交付区,哪些仍然处在探索区?
虽然整体架构已经成型,但能力成熟度并不是平均分布的 🛡️。
当前比较清晰的判断是:
- 在线问答和原生工具链路已经形成基础闭环。
report quick和report standard更接近稳定交付态(即“工程安全区”)。report deep仍然依赖更多外部 provider 和更强的失败治理(即“业务过渡区”)。research目前更适合作为 readiness checklist,而不是稳定上线能力(即“技术探索区”)。
这也是为什么我更愿意把当前系统定义为“已经脱离 demo,但仍在继续工程化”的阶段 🚀。
九. 演进罗盘:垂直智能体要啃下的下一个工程硬骨头
这一节不展开新功能,而是聚焦下一阶段最值得补强的基础能力。
从技术架构角度看,下一阶段最值得投入的,不是继续堆更多表面功能,而是继续收紧下面这些基础能力 🧭:
- 证据链的稳定性和可降级能力 🧱。
- 工作流失败路径的可观测性和可退款语义 📊。
- 更明确的工具边界和调用策略 ⚙️。
- 报告工件、运行记录和知识沉淀之间的统一数据契约 📄。
- 在线链路和离线链路之间更清晰的数据 freshness 管理 🔄。
如果这些基础能力继续站稳,后面的服务和业务扩展才不会变成不可维护的堆叠 🧱。
写在最后:不只做聊天机器人,要做跨境电商的重型装配线
最后用一句更产品化的话,重新定义这套系统的本质。
如果只用一句话概括这套系统,我会这样描述它 📝:
垂直智能体(Agent)不只是“一个会聊天的对话窗口”,而是一套围绕特定场景定制的多层编排服务系统。它的核心目标是:把自然语言问题转成可路由的请求、把业务分析任务转成可验证的证据链、再把证据链组装成可交付决策的报告工件 🚀。
对外它呈现出拟人化的智能体交互,对内它其实更像一条被持续工程化的重型产品装配线 🏭。